
В предыдущей части туториала мы научили наше изоморфное приложение проксировать запросы к backend api, с помощью сессии передавать начальный стейт между синхронными запросами и осуществлять Server-side rendering с возможностью переиспользования разметки на клиенте (hydrate). В этой части мы решим еще две ключевые проблемы изоморфных веб-приложений: изоморфный роутинг и навигация, и повторный фетчинг и начальное состояние данных. И сделаем это буквально 5-ю строками кода. Погнали! Читать…
Подробнее![[Перевод] Руководство по SEO JavaScript-сайтов. Часть 2. Проблемы, эксперименты и рекомендации](https://habrastorage.org/getpro/habr/post_images/76a/782/4fa/76a7824facadead0ad7490e76dcb1c19.jpg)
В первой части перевода этой статьи мы говорили о том, как веб-мастер может взглянуть на свой ресурс глазами Google, и о том, над чем стоит поработать, если то, что увидит разработчик сайта, окажется не тем, чего он ждёт. Сегодня, во второй части перевода, Томаш Рудски расскажет о наиболее распространённых SEO-ошибках, которым подвержены сайты, основанные на JavaScript, обсудит последствия грядущего отказа Google от механизма AJAX-сканирования, поговорит о предварительном рендеринге и об…
Подробнее
Представляем вашему вниманию перевод первой части материала, который посвящён поисковой оптимизации сайтов, построенных с использованием JavaScript. Речь пойдёт об особенностях сканирования, анализа и индексирования таких сайтов поисковыми роботами, о проблемах, сопутствующих этим процессам, и о подходах к решению этих проблем. В частности, сегодня автор этого материала, Томаш Рудски из компании Elephate, расскажет о том, как сайты, которые используют современные JS-фреймворки, вроде
Подробнее
В предыдущей части туториала мы узнали что такое проект RealWorld, определились целями туториала, выбрали стек технологий и написали простой веб-сервер на Express в качестве основы для изоморфного фронтенда. В этой части, мы допилим серверную часть и напишем изоморфный «Hello World» на Ractive, а также соберем все это с помощью Webpack. Читать дальше →
Подробнее
Весной 2017 года Eric Simons, со-основатель учебного проекта Thinkster, анонсировал проект «RealWorld» — демо приложение и спецификация к нему. Проект объявил своей целью выйти за рамки привычных «todo»-демок для более прикладного сравнения и изучения возможностей различных фреймворков и технологий, а также подходов к разработке и способов решения задач. Читать дальше →
Подробнее![[Перевод] Функция random() у гуглобота работает абсолютно детерминированно](https://habrastorage.org/getpro/habr/post_images/b46/36b/286/b4636b286290eaefb4ce759de9150c4c.png)
Я проводил некоторые эксперименты, как Googlebot разбирает и рендерит JavaScript, и наткнулся на несколько интересных вещей. Первое — то, что функция Math.random() в Googlebot выдаёт полностью детерминированные серии чисел. Я написал маленький скрипт, который использует этот баг для точной идентификации гуглобота: Источник При первом вызове Math.random() из гуглобота результат всегда будет 0,14881141134537756, второй вызов всегда вернёт 0,19426893815398216. Скрипт по ссылке выше просто…
Подробнее
Времена, когда обновления поисковых алгоритмов Google выкатывались крупными кластерами и носили любовно подобранные зоологические имена, остались позади. Осенью один из представителей компании небрежно заметил, что сейчас алгоритмы корректируются по несколько раз на дню и широкую публику оповещают только о незначительной части этих изменений. Этого стоило ожидать — по мере того, как искусственный интеллект набирает силу, развитие системы ранжирования и ускоряется, и становится менее дискретным.
ПодробнееWe don’t need no traffic building, We don’t need no SEO, No link exchanges in your network, Spammers! leave us all alone. Anna Filina Немного истории В далеком 2013 году Spike Brehm из Airbnb опубликовал программную статью, в которой проанализировал недостатки SPA-приложений (Single Page Application), и в качестве альтернативы предложил модель изоморфных веб-приложений. Сейчас чаще используется термин универсальные веб-приложение (см. дискуссию). В универсальном веб-приложении каждая…
Подробнее
Два года назад я написал статью "Справочник интернет-маркетолога", в которой собрано несколько десятков различных онлайн-сервисов, инструментов интернет-маркетинга. При желании обновить статью, были найдены подборки, после которых за свою становилось стыдно. Стало понятно что делать меньше 500 неинтересно. Это было непросто, но в итоге мы собрали 555 сервисов, по более чем 60 категориям: Читать дальше →
Подробнее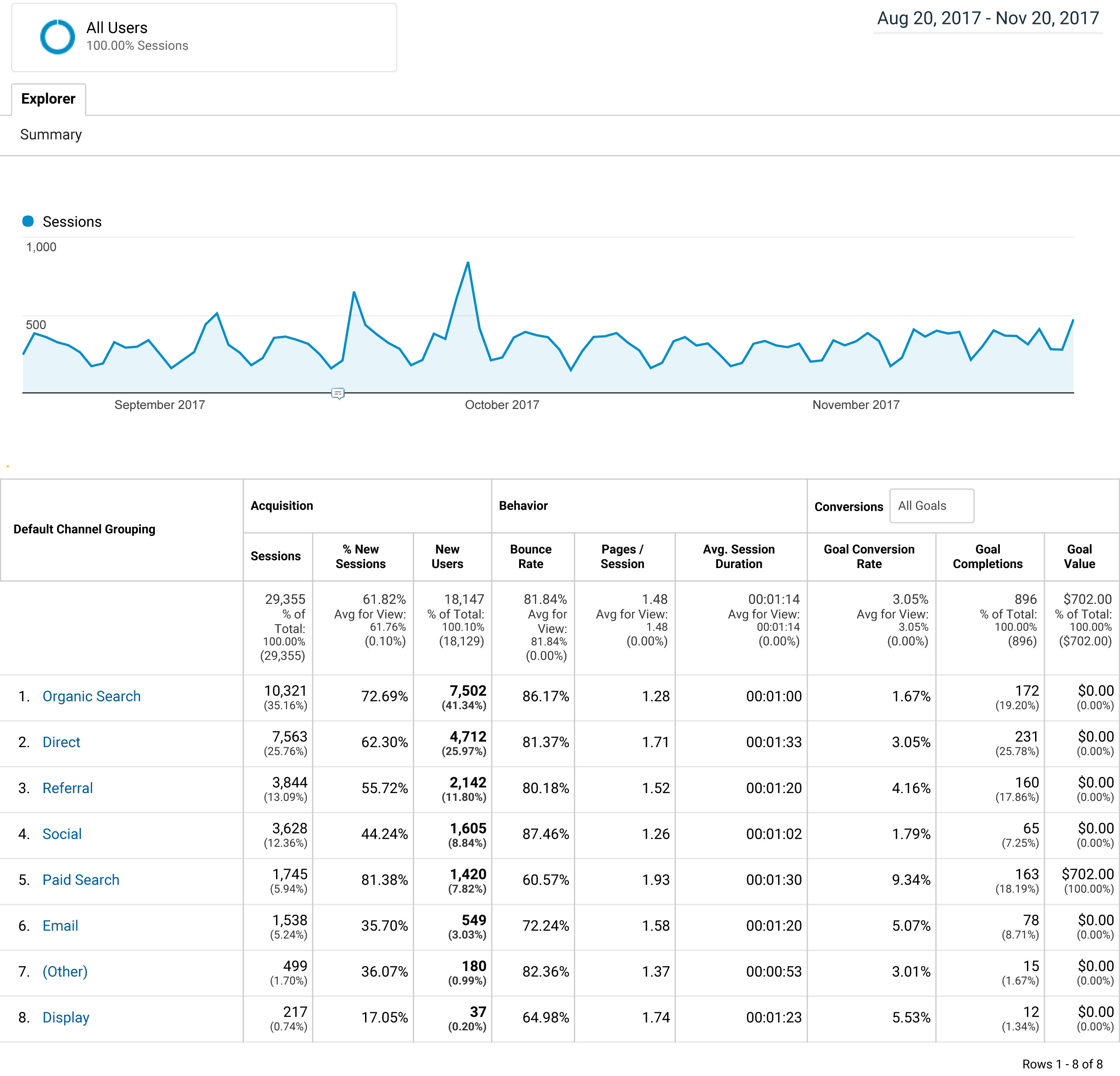
Задача следующая: есть компания по верстке веб-сайтов. Бюджет около $25.000. Владелец бизнеса интересуется возвратом инвестиций в SEO и AdWords. На первый взгяд сравнивать эти каналы привлечения клиентов сложно. Например результаты SEO-продвижения приходят через недели и месяцы, а вот контекстную рекламу анализировать и оптимизировать можно практически сразу. Тем не менее есть измеримые показатели: сумма инвестиций, количество уникальных посетителей, конверсия, количество сделок с
Подробнее
Мне казалось, что поисковики давно победили black hat тактики с помощью машинного обучения и других мощных технологий. Сети дорвеев если и остались, то только где-то на обочине интернета, в маргинальных тематиках типа казино или контента для взрослых. Но недавно я наткнулся сразу на целую кучу спамных сайтов, которые собирают миллионы посетителей из Яндекса, легко побеждают качественные и авторитетные проекты даже в белых нишах. Читать дальше →
Подробнее![[Перевод] Анализ файлов robots.txt крупнейших сайтов](https://habrastorage.org/getpro/habr/post_images/5a4/e51/25b/5a4e5125b5b0cc82e436bde5ee2410de.png)
Robots.txt указывает веб-краулерам мира, какие файлы можно или нельзя скачивать с сервера. Он как первый сторож в интернете — не блокирует запросы, а просит не делать их. Интересно, что файлы robots.txt проявляют предположения веб-мастеров, как автоматизированным процессам следует работать с сайтом. Хотя бот легко может их игнорировать, но они указывают идеализированное поведение, как следует действовать краулеру. По существу, это довольно важные файлы. Так что я решил скачать файл
Подробнее