Или: Как накормить нейросеть структурированным завтраком, а не овсяной кашей из XML 📡 Пролог: RSS не умер. Его просто… перестали слушать RSS был великим протоколом. В 2000-х он позволял читать любимые блоги без соцсетей, без алгоритмов, без рекламы. Это был открытый веб в чистом виде. Но в 2026 году RSS сталкивается с двумя проблемами. Проблема первая: XML — формат громоздкий. Парсить его не сложно, но неудобно. А нейросети любят JSON. Это их родной язык. Проблема вторая: RSS не заточен под
ПодробнееИли: Как монетизировать контент, когда поисковики перестали платить 🛡️ Пролог: Две стратегии, два мира В 2026 году чётко обозначились два подхода к контенту. Подход А (массовый, SEO-шный). Вы открываете доступ для всех: людей, ботов, нейросетей. Вы надеетесь, что вас увидят в поиске, процитируют в ответах, и это принесёт трафик. Вы генерируете тонны «оптимизированного» контента, чтобы нейросети вас заметили. Подход Б (закрытый, премиальный). Вы ограничиваете доступ. Часть контента — по
ПодробнееИли: Почему SEO-специалисты бегают по кругу, а владельцы сайтов теряют трафик 🎯 Пролог: Подмена, которую мы проглотили Нам сказали: «Оптимизируйте контент для нейросетей, и они будут вас цитировать. А цитирование приведёт кликов». Звучит логично. Но есть нюанс, о котором умалчивают. Если нейросеть уже дала пользователю готовый ответ, зачем ему переходить на ваш сайт? Он получил информацию. Он доволен. Он закрыл вкладку. Вы выиграли конкурс «быть процитированным». Но проиграли борьбу за переход.
Подробнее
Или: Как превратить ваш скучный XML-фид в изысканный JSON-десерт для AI-агентов и подписчиков Feedly 📡 Пролог: RSS не умер, он просто устал RSS был великим. Серьёзно. В 2000-х он позволил читать блоги без соцсетей, без алгоритмов, без рекламы. Это был открытый веб в чистом виде. Но время идёт. XML — формат громоздкий. Парсить его не сложно, но неудобно. А нейросети (и разработчики) любят JSON. Это их родной язык. И в 2017 году группа энтузиастов (включая создателя JSON, Дугласа Крокфорда)
Подробнее
Или как мы через 7 лет вернулись к идее публикации из email и сделали standalone-решение на чистом PHP В 2019 году мы опубликовали материал «Ищем разраба: DLE-PostingNews2email — Размещение новостей из сообщений электронной почты». Идея была простая: взять почтовый ящик, подключить его к DLE и дать авторам возможность писать статьи в привычном почтовом клиенте. Тогда проект не пошёл в серию — требовалось слишком много «костылей» под архитектуру DLE, а интерес со стороны заказчиков был точечным.
ПодробнееИли: Почему люди разучились читать, а нейросети — наоборот 🎤 Пролог: Вы ещё читаете? А зря Понаблюдайте за собой. Как часто вы читаете длинные статьи? Не пролистываете, не просматриваете диагонально, а именно читаете — слово за словом, абзац за абзацем? А как часто вы слушаете подкаст за рулём, смотрите короткое видео в ожидании кофе, отвечаете голосовым сообщением в Telegram? Причём последнее — даже не разговаривая, а просто надиктовывая текст, который собеседник прочитает глазами.
Подробнее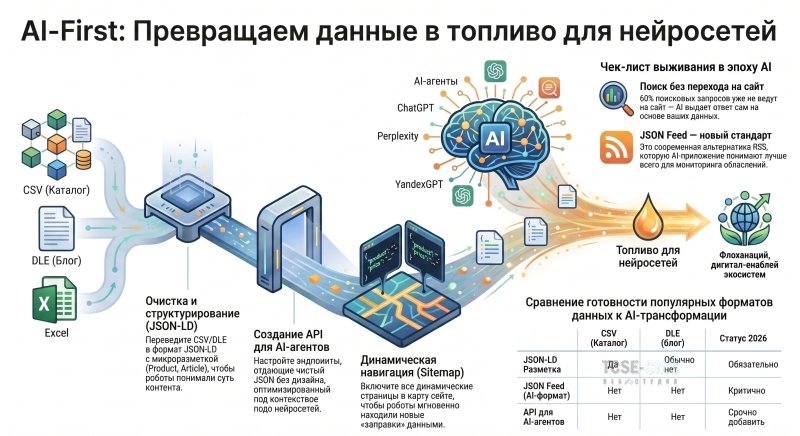
Или: Почему в 2026 году вам не нужен «сайт». Вам нужен API для роботов, которые приведут людей. 🧠 Пролог: Ваши данные — это нефть. Но она сырая У вас есть: База данных DLE с 10 000 статей за 10 лет. CSV-файл с остатками запчастей на складе (как в нашем кейсе). Excel-таблица с номенклатурой товаров. База клиентов из CRM. И это всё — чёрное золото, которое лежит у вас под ногами. Проблема в том, что оно сырое. Вы не можете залить его в бак нейросети и поехать. Классический сайт с красивым
Подробнее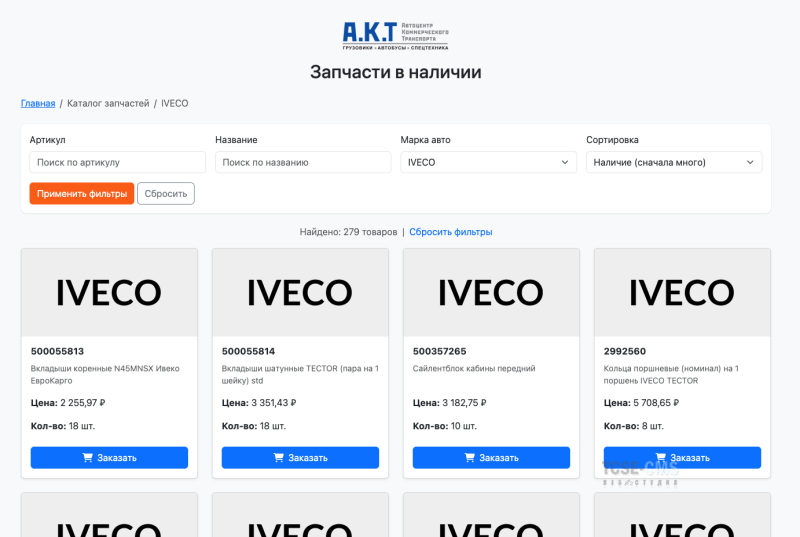
Реальный кейс: разработка набора PHP-скриптов для работы с товарными остатками Проблема: есть CSV, а сайта нет Представьте ситуацию: у заказчика есть огромный CSV-файл с товарными остатками запчастей. Десятки тысяч строк. Артикулы, названия, цены, наличие, марки автомобилей. Всё это добро лежит в файле, обновляется раз в месяц, но сайта, который мог бы это показать миру — нет. А если сайт и есть — он либо не работает, либо поисковый трафик к нему давно сошел на нет. Задача: быстро (и желательно
Подробнее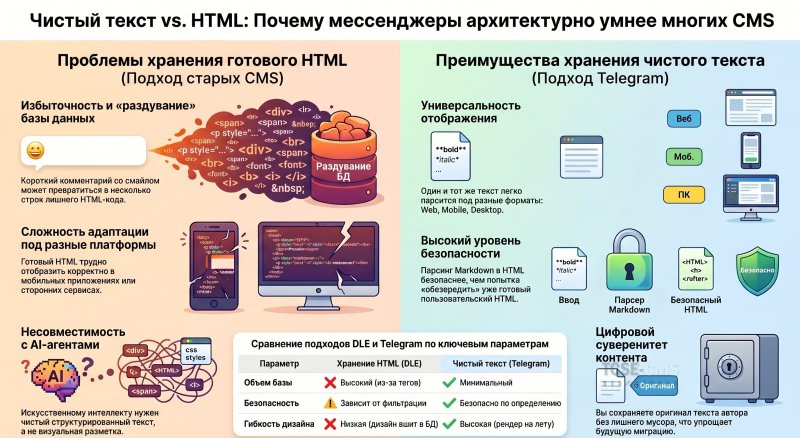
Или: Как BBCode, Markdown и вечный спор о безопасности привели к тому, что мессенджеры умнее CMS 📜 Пролог: Три эпохи, три подхода В начале был HTML. Честный, понятный, вездесущий. Вы писали жирный текст , и браузер его делал жирным. Проблема? Любой пользователь мог написать — и это срабатывало. В 2000-е годы это было весело (до первого взлома). Потом пришли форумы. Чтобы обычный пользователь не поломал сайт, придумали BBCode. Вместо <b>[.code] писали [b]. Вместо
Подробнее